Editor’s note: this article was originally published on the blog Old School Script. We have taken over its archives and are slowly republishing pieces that have continuing importance and value. This article was originally published December 1st, 2016. We continue to appreciate Kris Lyle’s willingness to share his writing with our readers here at Koine-Greek.com.

Sometimes big things happen right in front of us and we hardly notice. It could be we’re looking in the wrong spot or it could be that as “creatures of habit” we refuse to see anything else but what we’re accustomed to.
For nearly two decades — and more so in the past 5 to 10 years — there’s been a strong push among Cognitive linguists to adopt quantitative methods of analysis from Corpus Linguistics. The implications of such a change in methodology are noteworthy to say the least. So in case you’re looking in the wrong spot, or have found yourself content with the status quo, let me fill you in.
What is Cognitive Semantics?
Cognitive Semantics is a child of the 80’s, and like its predecessors is a response to former models of studying linguistic meaning. Instead of the classical model of categorization as well as modular or truth-conditional semantics, Cognitive Semantics opts for a view of meaning that is embodied and encyclopedic, and a model of categorization that looks to prototypes and allows for fuzzy boundaries (Glynn 2014:119).*
*Interestingly, in a study on the development of different theories of lexical semantics, Dirk Geeraerts (2010) has noticed how some of the key tenets of modern day Cognitive Semantics find their origins in Historical-Philological semantics (1830–1930). There is nothing new under the sun.
This move towards a theory of language based in actual usage — as opposed to how it “ought” to be — only complicated matters further. While Structuralism could rely on introspection via langue for falsification and Generativism on an ideal speaker’s competence (another face of introspection), for Cognitive Linguistics falsification is moved beyond reach… at least when introspection is the sole arbitrator (Glynn 2010:2). After all, how can one linguist (or many) be responsible for determining the gold standard of language when it’s assumed that no such thing exists? There is only what works; and what works is often fuzzy and messy and tailor-made by every user.
Although introspection is unfit for the type of analysis Cognitive Linguistics requires (at least to be falsifiable), its governing presence among former schools ensured that it would be hard to shake off. Eventually, however, a few key publications showed how ad hoc lexical semantic investigations had become; and this charge both stung and stuck (Glynn 2010:4).* It’s no longer uncommon for even introductory textbooks to acknowledge this weakness: “[one criticism is] the indeterminate and speculative nature of the analyses” (Introducing Semantics, Riemer 2010:254).
*Glynn (2010:4) cites Geeraerts (1993a) and Sandra & Rice (1995) as prophetic works calling out weaknesses in the current methods of doing lexical semantic research.
To be fair, linguists have been able to explain much with their own thinking caps filtered through a Cognitive framework. In fact, introspection by no means invalidates the conclusions arrived at — but neither does it validate them empirically. And this is the crux of the matter. Cognitive linguists have been coming to grips over the past few decades that their methodology must evolve more aggressively if the hypotheses and theories are to be replicable for testing and falsification. But how?
Cognitive Linguistics is beginning to realise the implications of its own theoretical framework.
— Dylan Glynn (2010:1)
What is corpus-driven Cognitive Semantics?
Although Cognitive Semantics has a history of relying on introspection, particularly with radial network analyses, there is a lineage of scholarship that has opted for more empirical methods since the field’s conception.
Dylan Glynn surveys key journals and works from 1980 to 2000 and classifies the articles according to their method of study (e.g., elicitation, introspection, observation) as well as the object and form of study; and he does so from both the angles of semasiology (polysemy) and onomasiology (synonymy). After some statistical analysis of the data he concludes that corpus-driven quantitative analysis is the natural next-step in the Cognitive program of lexical semantics.
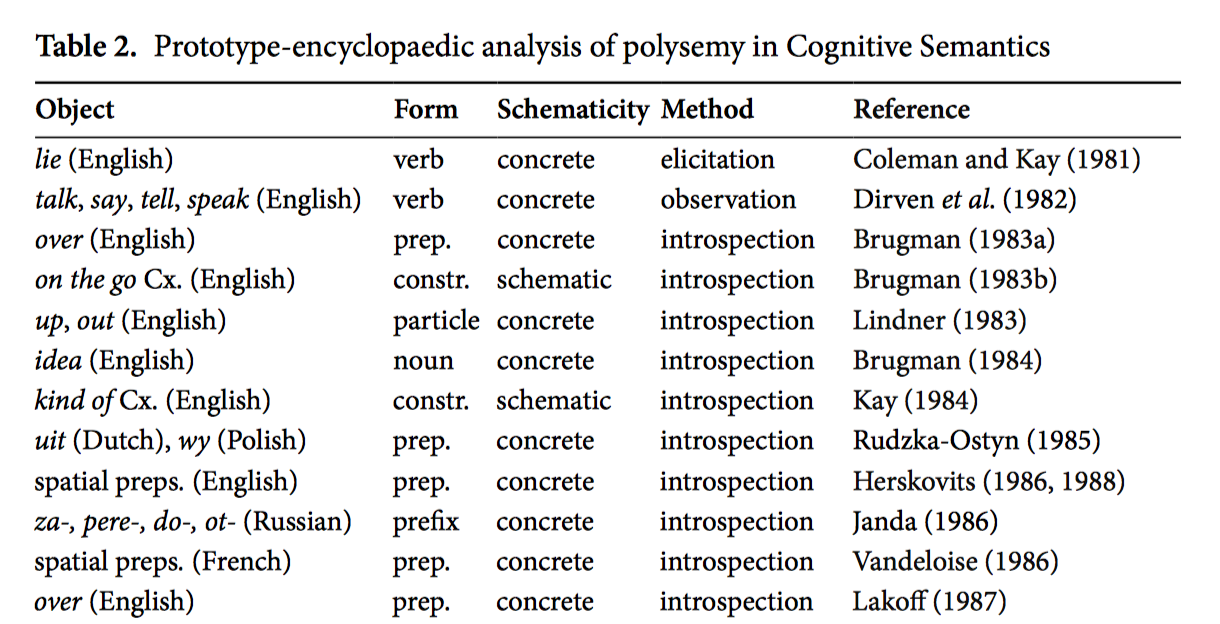 Semasiological sample from Glynn’s study
Semasiological sample from Glynn’s study 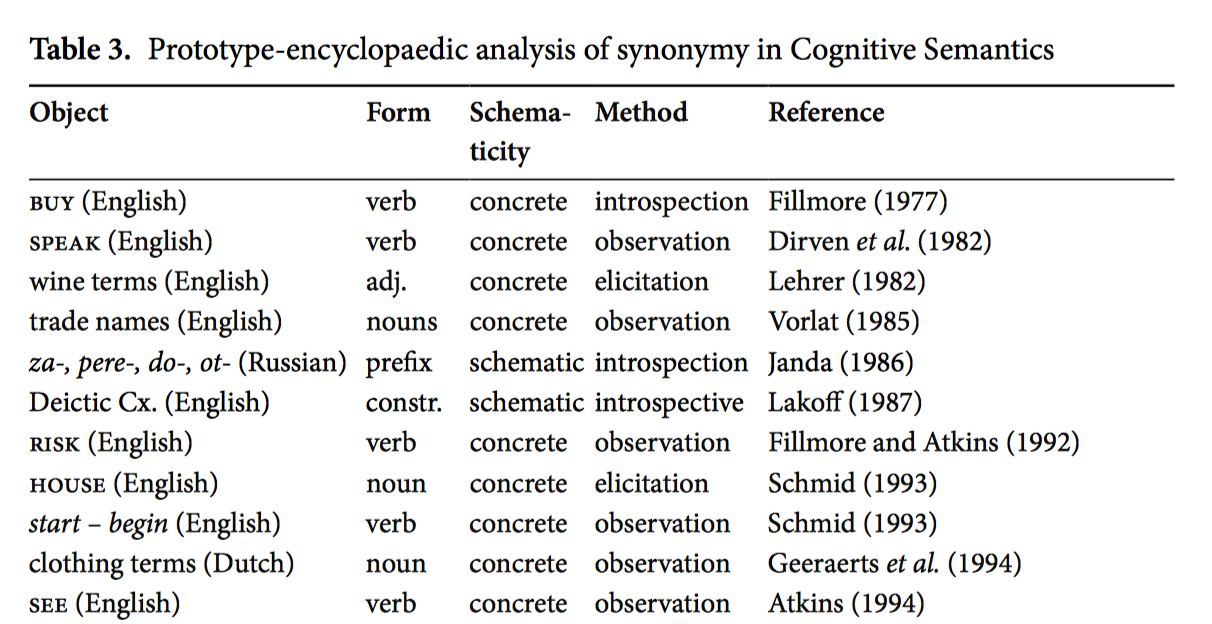 Onomasiological sample from Glynn’s study
Onomasiological sample from Glynn’s study 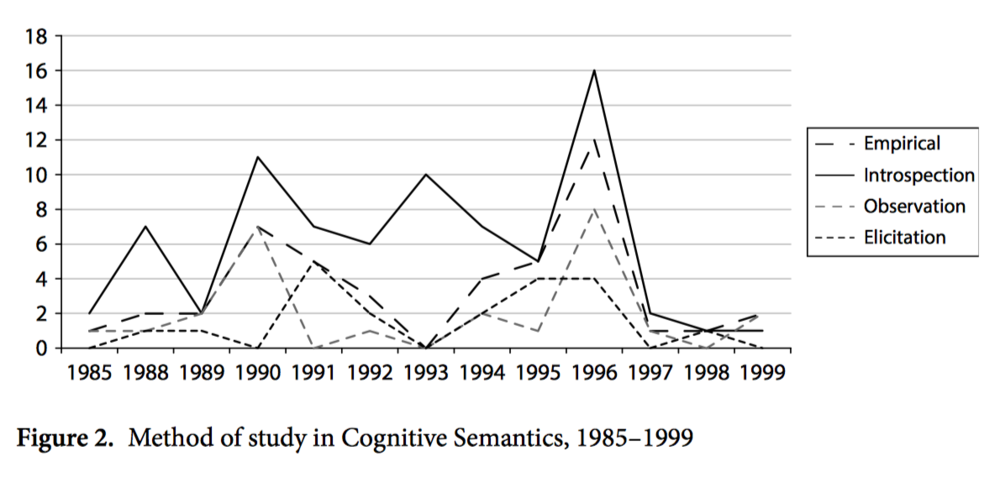 Method of Study (notice the consistent presence of empirical methods)
Method of Study (notice the consistent presence of empirical methods)
Quantitative corpus-driven methods are, therefore, not a new turn or a new direction, but the natural development of an existing tradition.
— Dylan Glynn (2014:25)
But what is a quantitative corpus-driven method?
The essential ingredients are already hinted at in the description: it is 1) corpus-based, and 2) quantitative. It is corpus-based in the sense that no ad hoc uses of language are studied. In other words, made-up sentences or “perfect examples” are not dreamed up or crafted to explore or prove one’s point. Instead, the object of study comes from language recorded in real life. It is 100% usage-based. This type of language data is generally pulled from a huge digital corpus; hence the name “corpus-driven” or “corpus-based.”
The focus on drawing language data from a corpus is related to the second factor of this corpus-driven method, that it is quantitative. Corpus Linguistics (among other disciplines, like psychology) has a variety of quantitative techniques at its disposal to analyze large and complex chunks of data in a systematic way. A few dozen of these have been co-opted by Cognitive linguists over the years and appropriated to lexical semantic endeavors.
This process of operationalization is a difficult undertaking even in the physical domain; it is all the more difficult for disciplines dealing with intangibles such as linguistic meaning.
— Anatol Stefanowitsch (2010:356)
A necessary step in the application of these models is the operationalization of semantic categories. Operationalization is a big word that refers to the process of converting categories like entrenchment, senses, and prototypicality into objects of study that are measurable. A standard method for redefining categories that are qualitative is to make them quantitative — at least for research purposes.
As stated above, once a corpus has been selected and the variables have been operationalized, there are a number of quantitative techniques that can be used to explore the data in search for meaningful correlations. These techniques can be divided into two camps: “one based on observable formal patterns (collocation analysis) and another based on patterns of annotated usage-features of use (feature analysis)” (Glynn 2014:307). Arguably the most popular method from the former camp is collostructional analysis, and for the latter is behavioral-profile analysis (or multifactorial usage-feature analysis).*
*Collostructional Analysis is actually a suite of methods that was put forward in a series of articles by Stefan Gries and Anatol Stefanowitsch: Stefanowitsch and Gries (2003, 2005) and Gries and Stefanowitsch (2004a, 2004b). An excellent overview of this approach is offered by Hilpert (2014:391–404). A sample of articles that use a Behavioral Profile analysis are the following: Divjak and Gries (2006), Glynn (2009, 2010), Gries (2006, 2010), and Gries and Divjak (2009).
While this is only the tip of the iceberg for both the number and types of quantitative techniques available (and we haven’t even covered how to do one), it’s enough to understand where the “quantitative” aspect comes from in the description of a methodology that is considered both quantitative and corpus-based.
In physical science the first essential step in the direction of learning any subject is to find principles of numerical reckoning and practicable methods for measuring some quality connected with it. […] More simply: To measure is to know.
In physical science the first essential step in the direction of learning any subject is to find principles of numerical reckoning and practicable methods for measuring some quality connected with it. […] More simply: To measure is to know.
In physical science the first essential step in the direction of learning any subject is to find principles of numerical reckoning and practicable methods for measuring some quality connected with it. […] More simply: To measure is to know.
— Lord Kelvin (1883) “Electrical Units of Measurement”
What are the benefits?
It cannot be overestimated how significant it is for semantic inquiries to have the potential to be carried out as an empirical exercise.* With an operationalized object of study and a replicable methodology, the potential for falsifiability is introduced into the equation. And if the study is not falsified, then it stands to reason — under the working assumptions — that the conclusions have a good chance of being correct (or at least, not wrong). This is far from armchair semantics, hunch theories, or placing one’s faith in the expert opinion of a linguist.
*I use the word “empirical” here in line with all the literature I have read so far that characterizes itself as part of a movement of quantifying semantics. For instance, see the description of a group of linguists at Leuven that seem to be spearheading this charge: Quantitative Lexicology and Variational Linguistics (QLVL). I agree with Jeremy Thompson (who commented on an earlier draft of this post) that more could/should be said about what is meant by this term; especially given that linguistics is more of a soft/social science than a hard/physical one, which by nature has implications for how a study can be considered empirical.
The model of language proposed by Cognitive Linguistics is so completely simple that it places the emphasis squarely on method and data.
— Glynn (2010:2)
It would be a mistake, however, to think that quantitative corpus-driven methods invalidate the need or remove the presence of introspection. Far from it. Introspection plays a key role in different parts of the process depending on the quantitative technique employed. For instance, collocation analysis tends to begin on an objective footing while usage-feature analysis introduces more subjective decisions. With the former, the analyst must take the collocation as it comes (e.g., ditransitive or better-not-[verb] constructions), whereas with the latter, the analyst chooses which features to annotate and how — which varies on the spectrum of objectivity (e.g., morphological features are more objectively identified than semantic ones). But in the end, with either approach, it is the researcher that must make sense of the data and interpret the results. The requirement of introspection in the process does not make quantitative corpus-driven methods any less empirical. Scientists in other fields must also define their variables and interpret the experiment’s results. The advantage to corpus-driven Cognitive Semantics is not, therefore, the removal of subjectivity but its union with objective methods.
Aside from the achievement of providing a means to do empirical semantics, another significant benefit of quantitative corpus-driven Cognitive Semantics is that it takes seriously some of the distinctive pillars of Cognitive Linguistics. For instance, the commitment to corpus-data as the object of study aligns with Cognitive Linguistics’ claim that the only type of language worth studying is that which is used (contra other paradigms that hold up an ideal speaker versus the language in play) (Evans and Green 2006: ch. 4).
A necessary but complicating implication of this commitment is the complexity of natural language that must be dealt with in an empirical manner. Language is a complex system. No single use of any expression is the same as what was uttered before or will be uttered in the future. The context in the broadest sense is completely different, and so is the use as it relates to that milieu. Each person uses language in their own way, and factors like age, culture, and location all play into how language-use should be accounted for. In this way, as with any other complex system, there is no model that could ever account for the infinite variability of language (Andrason 2016:21–26). The best that can be done is a close approximation.
In light of this complexity, Cognitive Linguistics has opted for an encyclopedic view of meaning — one that does not restrict lexical meaning to that which is closely/obviously related to the form in question but extends the type of knowledge that is relevant and required to broader, real-world associations (Evans & Green 2006: sections 5.1.3 and 5.2.3). This stance is much closer to linguistic realities than previous models of meaning (e.g., dictionary senses, necessary-and-sufficient conditions, computational semantics, etc.). But how does corpus-driven Cognitive Semantics operationalize an encyclopedic understanding of meaning?
What is “arguably the most important facet of corpus-driven semantic research” (Glynn 2010:17) is its ability to perform multifactorial analysis. This type of analysis is able to capture as many aspects of a target object that is deemed necessary to account for — from traditional grammatical roles to socio-cultural variables. So rather than completely flatten the complexity of language or dilute its dynamism, quantitative techniques have methods to preserve it.
You shall know a word by the company it keeps!
— J.R. Firth (1962:11)
A related benefit of using multivariate methods is how the data outputs more closely reflect the conceptual structure of meaning. More specifically, instead of positing distinct senses (a relic from Structuralism), multivariate methods like the Behavioral Profile approach (mentioned above) yield a configuration of usage-features without specifying what this represents. It’s up to analyst to infer whether these clusters of data-points signify conventionalized usages. What is important to note is that the data output of these methods does not play into the notion of distinct senses, but instead suggests a model of conceptual structure that is more cognitively plausible: that of non-discrete lexical usages. (I’ve written more on this benefit here, “A New Model for Mapping Meaning”.)
Finally, a major and obvious advantage of quantitative corpus-driven methods is their ability to juggle large-scale inventories of data (e.g., tokens and annotations), and all the while churn the data through statistical equations to produce outputs no single mind could hope to. For instance, Stefan Gries (2006) performed a behavioral profile analysis of the verb “to run”: this involved starting with 815 tokens, tagging each with 252 variables relating to usage, which resulted in 205,000 data points. The potential patterns of correlation between these variables is simply too great to manage; but a quantitative model — like cluster analysis — is fit to help you explore the data and not miss meaningful connections.
All in all, quantitative corpus-driven Cognitive Semantics provides a researcher with a framework for taking seriously the major pillars of Cognitive Linguistics, not just in theory but in methodological practice — specifically, by operationalizing actual language use and accounting for the complexities of this socio-linguistic phenomenon through multivariate modeling.
a combination of the usage-based model and corpus-driven research resolves some of the great debates of 20th century linguistics
— Glynn (2010:5)
tl;dr
Corpus-driven Cognitive Semantics is a usage-based model of semantic inquiry that relies on the ability to render the object of study (meaning) into something that is measurable, which in turn allows quantitative techniques to be employed that are both replicable and falsifiable, thus upping the empirical status of the research.
Where do I dive in?
I’d suggest starting with Dylan Glynn’s introduction to this niche field. Also, you won’t go wrong by consulting any of the relevant publications I cited above and list below in the bibliography. The majority of linguists participating in this shift seem sensitive to the learning curve and I have no doubt you’ll find their writing reflects this.
Bibliography
Andrason, A. “A complex system of complex predicates: tense, taxis, aspect and mood in Basse Mandinka from a grammaticalisation and cognitive perspective.” PhD diss., University of Stellenbosch, 2016.
Divjak, D., & Gries, St. Th. (2006). Ways of trying in Russian: Clustering behavioral profiles. Corpus Linguistics and Linguistic Theory, 2, 23–60.
Evans, V. & Green, M. (2006). Cognitive Linguistics: An introduction. Edinburgh: Edinburgh University Press.
Firth, J.R. (1962). “A synopsis of linguistic theory 1930–1955,” in Studies in Linguistic Analysis, 1–32. Oxford: Blackwell.
Glynn, D. (2009). Polysemy, syntax, and variation: A usage-based method for Cognitive Semantics. In V. Evans, & S. Pourcel (Eds.), New directions in Cognitive Linguistics (pp. 77–106). Amsterdam & Philadelphia: John Benjamins.
Glynn, D. (2010). Synonymy, lexical fields, and grammatical constructions: A study in usage-based Cognitive Semantics. In H.J. Schmid, & S. Handl (Eds.), Cognitive foundations of linguistic usage-patterns: Empirical studies (pp. 89–118). Berlin & New York: Mouton de Gruyter.
Glynn, D. (2010c). Corpus-driven Cognitive Semantics: An overview of the field. In D. Glynn, & K. Fischer (Eds.), Quantitative Cognitive Semantics: Corpus-driven approaches (pp. 1–42). Berlin & New York: Mouton de Gruyter.
Glynn, D. (2014a). Polysemy and Synonymy: Cognitive theory and corpus method. In D. Glynn, & J. Robinson (Eds.), Corpus Methods for Semantics: Quantitative studies in polysemy and synonymy (pp. 7–38). Amsterdam & Philadelphia: John Benjamins Publishing Company.
Glynn, D. (2014b). Techniques and Tools: Corpus methods and statistics for semantics. In D. Glynn, & J. Robinson (Eds.), Corpus Methods for Semantics: Quantitative studies in polysemy and synonymy (pp. 307–341). Amsterdam & Philadelphia: John Benjamins Publishing Company.
Gries, S. Th. (2006). Corpus-based methods and Cognitive Semantics: The many senses of to run. In S. Th. Gries & A. Stefanowitsch (eds.), Corpora in Cognitive Linguistics: Corpus-based approaches to syntax and lexis (pp. 57–99). Berlin & New York: Mouton de Gruyter.
Gries, S. Th. (2009). “What is Corpus Linguistics?” Language and Linguistics Compass 3, 1–17.
Gries, St. Th. (2010). Behavioral profiles: A fine-grained and quantitative approach in corpus-based lexical semantics. The Mental Lexicon, 5, 323–346.
Gries, St. Th., & Divjak, D. (2009). Behavioral profiles: A corpus-based approach to cognitive semantic analysis. In V. Evans, & S. Pourcel (Eds.), New directions in Cognitive Linguistics (pp. 57–75). Amsterdam & Philadelphia: John Benjamins.
Hilpert, M. (2014). Collostructional analysis: Measuring associations between constructions and lexical elements. In D. Glynn, & J. Robinson (Eds.), Corpus Methods for Semantics: Quantitative studies in polysemy and synonymy (pp. 7–38). Amsterdam & Philadelphia: John Benjamins Publishing Company.
Riemer, N. Introducing Semantics. Cambridge: Cambridge University Press, 2010.
Stefanowitsch, A. (2010). Empirical cognitive semantics: Some thoughts. In D. Glynn, & K. Fischer (Eds.), Quantitative Cognitive Semantics: Corpus-driven approaches (pp. 355–380). Berlin & New York: Mouton de Gruyter.
